リアルタイムパフォーマンスの評価#
導入#
Autoware は、サービスに統合された場合、リアルタイム システムである必要があります。したがって、各コールバックの応答時間は可能な限り短くする必要があります。Autoware が遅いと思われる場合は、パフォーマンス測定を実施し、分析に基づいて改善を実装することが不可欠です。ただし、Autoware は多数の ROS 2 ノードで構成される複雑なソフトウェア システムであるため、ボトルネックを特定するプロセスが複雑になる可能性があります。この課題に対処するために、Autoware の詳細なパフォーマンス測定を実行する方法について説明し、ケース スタディを提供します。OS 層でのスケジューリングやメモリ割り当てなど、複数の要因がパフォーマンス低下の原因となる可能性があることは注目に値しますが、このページではユーザー コードのボトルネックに焦点を当てます。このセクションの概要は次のとおりです:
- 性能測定
- 単一ノードの実行
- 分割コアの準備
- 単一ノードを個別に実行する
- 計測と可視化
- ケーススタディ
- 計測コンポーネント
- 計画コンポーネント
性能測定#
正確な測定がなければ改善は不可能です。 アプリケーション コードのパフォーマンスを測定するには、外部の影響を排除することが不可欠です。 このような影響には、オペレーティング システムからの干渉や CPU 周波数の変動が含まれます。 スケジューリングの影響は、コア リソースが複数のスレッドで共有されている場合にも発生します。 このセクションでは、特定のノードのアプリケーション コードのパフォーマンスを正確に測定する手法の概要を説明します。 このセクションでは Intel CPU 上の Linux の場合についてのみ説明しますが、他の環境でも同様の考慮事項を行う必要があります。
単一ノードの実行#
スケジューリングの影響を排除するには、Autoware システム全体が実行されているときと同じロジックを使用して、測定対象のノードが独立して動作する必要があります。
これを実現するには、Autoware システム全体の実行中に、測定対象のノードのすべての入力トピックを記録します。
この目的を達成するために、ros2_single_node_replayer というツールが用意されています。
ツールの使用方法の詳細については、README を参照してください。
このツールは、Autoware 操作全体を通じて特定のノードの入力トピックを記録し、同じロジックを使用して単一ノードで再生します。
このツールはros2 bag recordコマンドに依存しており、ROS 2 Humble の時点ではサービス/アクションの記録はサポートされていないため、サービス/アクションをメイン ロジックとして使用するノードは適切に動作しない可能性があります。
分割コアの準備#
たとえば、上記の構成では、測定対象のノードはコア 2 で実行され、ハイパースレッディング ペアであるコア 8 も分離されていると仮定します。どのコアで測定対象を実行するか、どのノードを分離するかは、測定マシンのキャッシュとコアのレイアウトに基づいて適切に決定する必要があります。を実行すると、正しく構成されているかどうかを簡単に確認できますcat /proc/softirqs。intel_pstate=disableカーネルブートパラメータに指定されているため、userspaceスケーリングガバナーでも指定可能です。
測定対象のノードを実行する分離コアは以下の条件を満たす必要があります。
- CPU周波数を修正し、ターボブーストを無効にする
- タイマーの中断を最小限に抑える
- オフロード RCU (読み取りコピー更新) コールバック
- ハイパースレッディングが有効な場合、ペアになったコアを分離します
Linux でこれらの条件を満たすには、次のカーネル構成を使用したカスタム カーネル ビルドが必要です。 カスタム Linux カーネル(このようなもの)を構築する方法を説明するリソースは数多くあります。 フルティックレスが有効な場合でも、1 つのコアに 3 つ以上のタスクが存在する場合、スケジューリングのためにタイマー割り込みが生成されることに注意してください。
# Enable CONFIG_NO_HZ_FULL
-> General setup
-> Timers subsystem
-> Timer tick handling (Full dynticks system (tickless))
(X) Full dynticks system (tickless)
# Allows RCU callback processing to be offloaded from selected CPUs
# (CONFIG_RCU_NOCB_CPU=y)
-> General setup
-> RCU Subsystem
-*- Offload RCU callback processing from boot-selected CPUs
さらに、カーネルブートパラメータを次のように設定する必要があります。
GRUB_CMDLINE_LINUX_DEFAULT=
"... isolcpus=2,8 rcu_nocbs=2,8 rcu_nocb_poll nohz_full=2,8 intel_pstate=disable”
たとえば、上記の構成では、測定対象のノードはコア 2 で実行され、ハイパースレッディング ペアであるコア 8 も分離されていると仮定します。
どのノードを分離するかは、測定マシンのキャッシュとコアのレイアウトに基づいて適切に決定する必要があります。
cat /proc/softirqsを実行すると、正しく構成されているかどうかを簡単に確認できます。
intel_pstate=disableがカーネルブートパラメータに指定されているため、スケーリングガバナーでuserspaceも指定可能です。
cat /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor // ondemand
sudo sh -c "echo userspace > /sys/devices/system/cpu/cpu2/cpufreq/scaling_governor"
これにより、定義された範囲内で希望の周波数を自由に設定できます。
sudo sh -c "echo <freq(kz)> > /sys/devices/system/cpu/cpu2/cpufreq/scaling_setspeed"
Intel CPU ではターボ ブーストをオフにする必要がありますが、これは見落とされがちです。
sudo sh -c "echo 0 > /sys/devices/system/cpu/cpufreq/boost"
単一ノードを個別に実行する#
ros2_single_node_replayerのREADMEの指示に従ってノードを起動し、ツールによって作成された専用の rosbag を再生します。
rosbag を再生する前に、ノードが実行されるスレッドの CPU アフィニティを適切に設定し、用意された分離コアにノードが配置されるようにします。
taskset --cpu-list -p <target cpu> <pid>
最終レベルのキャッシュでの干渉を回避するには、測定中に実行する他のアプリケーションの数を最小限に抑えます。
計測と可視化#
測定ターゲットのパフォーマンスを視覚化するには、タイムスタンプとパフォーマンス カウンタ値をログに記録するコードをターゲットのソース コードに埋め込みます。
この目的を達成するために、pmu_analyzer というツールが用意されています。
ツールの使用方法の詳細については、README を参照してください。 このツールは、ソース コード内の任意のセクションの所要時間を測定できるだけでなく、さまざまなパフォーマンス カウンターも測定できます。
ケーススタディ#
このセクションでは、パフォーマンスの向上を実証するいくつかのケーススタディを紹介します。これらの例は、システムの効率向上に対する当社の取り組みを示すだけでなく、独自のプロジェクトで同様の課題に直面する可能性のある開発者にとって貴重なリソースとしても役立ちます。ここで説明するパフォーマンスの向上は、計測モジュールや計画モジュールなど、Autoware システムのさまざまなコンポーネントに及びます。どの点がボトルネックとなっているかは、コンポーネントごとに傾向があります。これらのケーススタディで使用されている方法、テクニック、ツールを検討することで、読者は Autoware のような複雑なソフトウェア システムを最適化する実践的な側面をより深く理解できるようになります。
計測コンポーネント#
まずはring_outlier_filterノードを例に性能向上の手順を説明します。
詳細についてはプルリクエストを参照してください。
次の図は、上記の"パフォーマンス測定"のセクションで説明したように分析された、ring_outlier_filterの主要処理部分の所要時間を時系列にプロットしたものです。
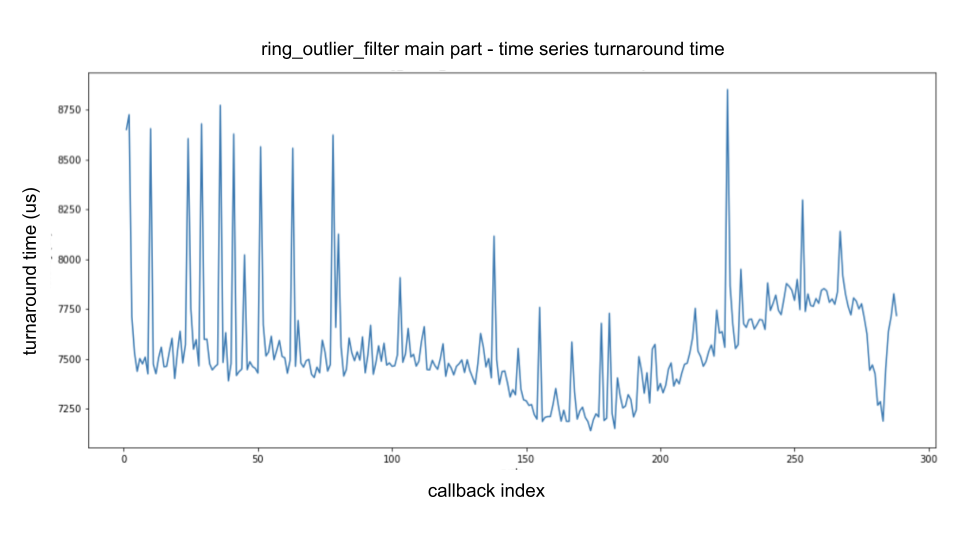
横軸は呼び出されたコールバックの数 (つまり、コールバック インデックス) を示し、縦軸は所要時間を示します。
計測モジュールの性能をパフォーマンスカウンタの観点から分析する場合はinstructions、LLC-load-misses、LLC-store-misses、cache-misses、minor-faultsに注意してください
パフォーマンス カウンタの分析によると、最大の変動はminor-faults (ソフト ページ フォールトなど)、2 番目に大きいのはLLC-store-missesおよびLLC-load-misses (最終レベル キャッシュでのキャッシュ ミスなど), 最も遅い変動はinstructions (メッセージデータサイズの変動等)によるものであることがわかります。
たとえば、横軸にminor-faults、縦軸に所要時間をプロットすると次のような支配的な比例関係がわかります。
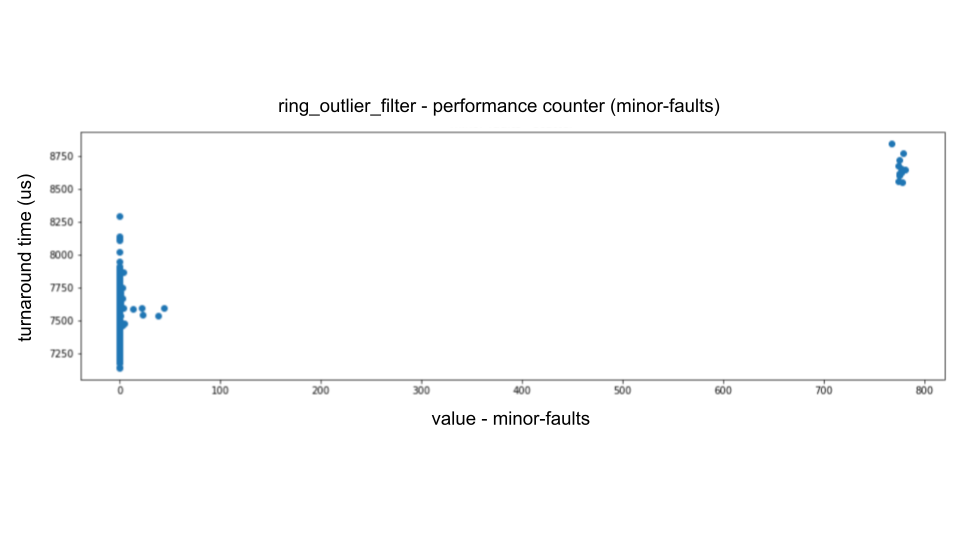
ソフト ページ フォールトをゼロにするには、事前に最初にアクセスされた領域からのみヒープ割り当てを行う必要があります。
Autoware コールバックの実行中にソフト ページ フォールトを回避するために、heaphookというライブラリを開発しました。
興味がある場合は、GitHubのディスカッションと問題を参照してください。
LLC ミスを減らすには、ワーキング セットを減らし、キャッシュ効率の高いアクセス パターンを使用する必要があります。
LiDAR 点群データなどの大規模なメッセージ データを扱う計測コンポーネントでは、コピーを最小限に抑えることが重要です。
センサー データ メッセージ タイプを入力および出力として受け取るコールバックは、可能な限りインプレース アルゴリズムで作成する必要があります。
これは、次の疑似コードでは、output_msgをinput_msgから生成するときに、メモリ コピーの数を減らすためにバッファの使用をできるだけ避けることが重要であることを意味します。
void callback(const PointCloudMsg &input_msg) {
auto output_msg = allocate_msg<PointCloudMsg>(output_size);
fill(input_msg, output_msg);
publish(std::move(output_msg));
}
キャッシュ効率を向上させるには、散発的にメモリ領域にアクセスするのではなく、可能な限りインプレース スタイルを実装します。 PCLを使ったROSアプリケーションでは、以下のようなコードがよく見られます。
void callback(const sensor_msgs::PointCloud2ConstPtr &input_msg) {
pcl::PointCloud<PointT>::Ptr input_pcl(new pcl::PointCloud<PointT>);
pcl::fromROSMsg(*input_msg, *input_pcl);
// Algorithm is described for point cloud type of pcl
pcl::PointCloud<PointT>::Ptr output_pcl(new pcl::PointCloud<PointT>);
fill_pcl(*input_pcl, *output_pcl);
auto output_msg = allocate_msg<sensor_msgs::PointCloud2>(output_size);
pcl::toROSMsg(*output_pcl, *output_msg);
publish(std::move(output_msg));
}
PCL ライブラリを使用するには、コールバックの開始時と終了時にメッセージ タイプ変換を実行するためにfromROSMsg()とtoROSMsg()が使用されます。
これは無駄なコピープロセスであるため、避けるべきです。
PCL(例、 https://github.com/tier4/velodyne_vls/pull/39)への依存関係を削除して、不要な型変換を排除する必要があります。
マップ データなどの大きなメッセージ タイプの場合、物理メモリの観点から、システム全体にインスタンスが 1 つだけ存在する必要があります。
計画コンポーネント#
まず、ターンアラウンドタイムが長くなりがちなbehavior_velocity_planner内のdetection_areaモジュールをピックアップします。
上記のパフォーマンス分析手順に従って、次のグラフを取得しました。
軸はセンシング事例のグラフと同じです。
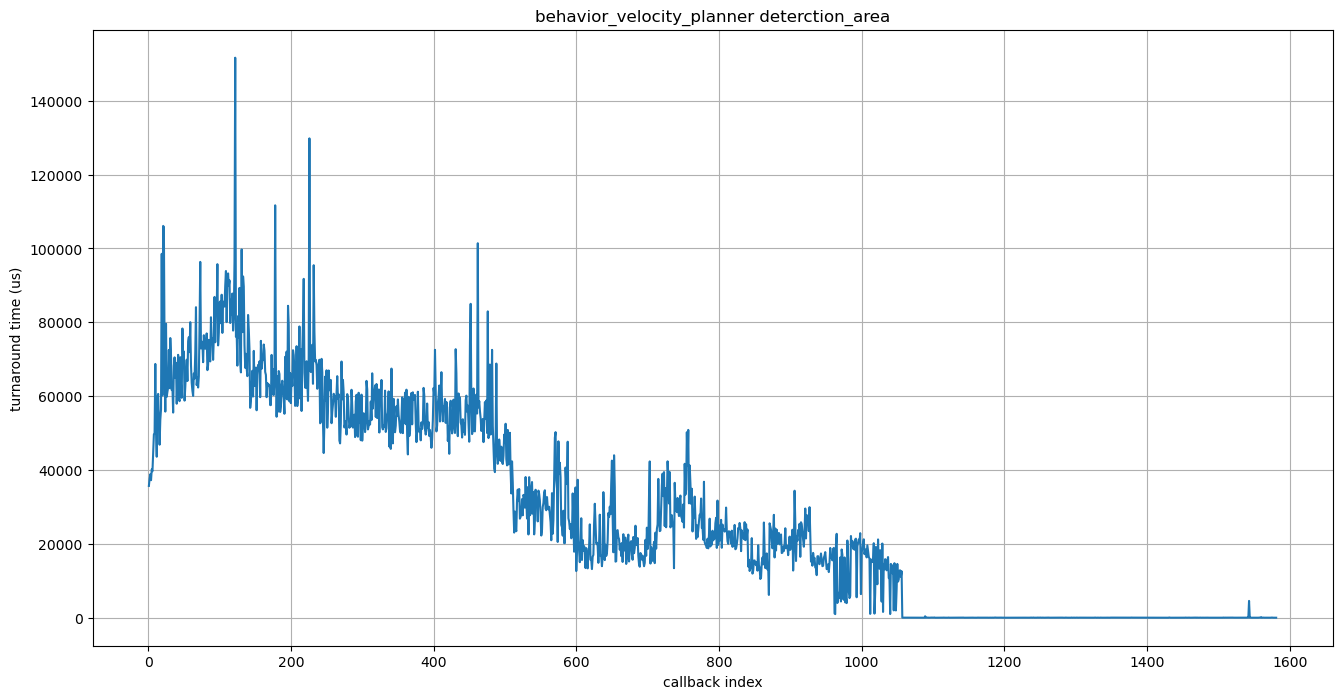
pmu_analyzerツールを使用してpmu_analyzerボトルネックをさらに特定したところ、次の複数のループが多くの処理時間を費やしていることがわかりました:
for ( area : detection_areas )
for ( point : point_clouds )
if ( boost::geometry::within(point, area) )
// do something with O(1)
各点群が各検出領域に含まれるかどうかを確認します。
Nをpoint_cloudsのサイズ、Mをdetection_areasのサイズとすると、withinの計算量はO(N)であるため、このプログラムの計算量はO(N^2 * M)になります。ここで、ほとんどの点群が特定の検出エリアから遠く離れた位置にあるとすると、特定の最適化を達成できます。 ず、検出領域を完全に覆う最小の外接円を計算し、その円内に点が含まれるかどうかを確認します。ほとんどの点群はこの方法ですぐに除外できるため、ほとんどの場合、 within 関数を呼び出す必要はありません。以下は最適化後の擬似コードです。
for ( area : detection_areas )
circle = calc_minimum_enclosing_circle(area)
for ( point : point_clouds )
if ( point is in circle )
if ( boost::geometry::within(point, area) )
// do something with O(1)
最小外接円に O(N) アルゴリズムを使用することにより、このプログラムの計算量はほぼ O(N * (N + M)) に減少します (正確な計算量は実際には変化しないことに注意してください)。 興味がある場合は、プル リクエストを参照してください。
この例と同様に、計画コンポーネントでは、数千から数万の点群、自分のルートを表す経路上の数千の点、周囲の障害物や検知エリアを表すポリゴンを考慮して、経路の作成を繰り返します。それらに基づいて。したがって、for ループを使用して点群とパスの内容に複数回アクセスします。ほとんどの場合、ボトルネックはこれらの単純な for ループにあります。ここで、Big O 記法を理解し、計算の複雑さの次数を減らすことは、パフォーマンスの向上に直接つながります。